Why Connecting Claude to HubSpot and GA4 Gives Wrong Revenue Answers and How Context Engineering Fixes It
TL;DR: Connecting Claude to HubSpot — and, with the current generation of connector tooling, GA4 — takes minutes, not days. Many of the answers you get in the first week will be wrong. Confidently, fluently wrong. The model isn't broken. The data isn't ready.
What sits between I plugged it in and I trust the numbers is context engineering: a metadata layer that tells the agent what your data actually means, AI-ready data preparation that resolves inconsistencies no dashboard surfaces, and explicit rules for when the agent should answer I don't have a reliable answer instead of inventing one.
It isn't a full enterprise semantic layer. That's a separate project on a different timeline. It's the realistic layer in between for B2B SaaS teams that need trustworthy AI revenue answers now.
The MCP server gives Claude access to your data. It doesn't give Claude understanding of your business.
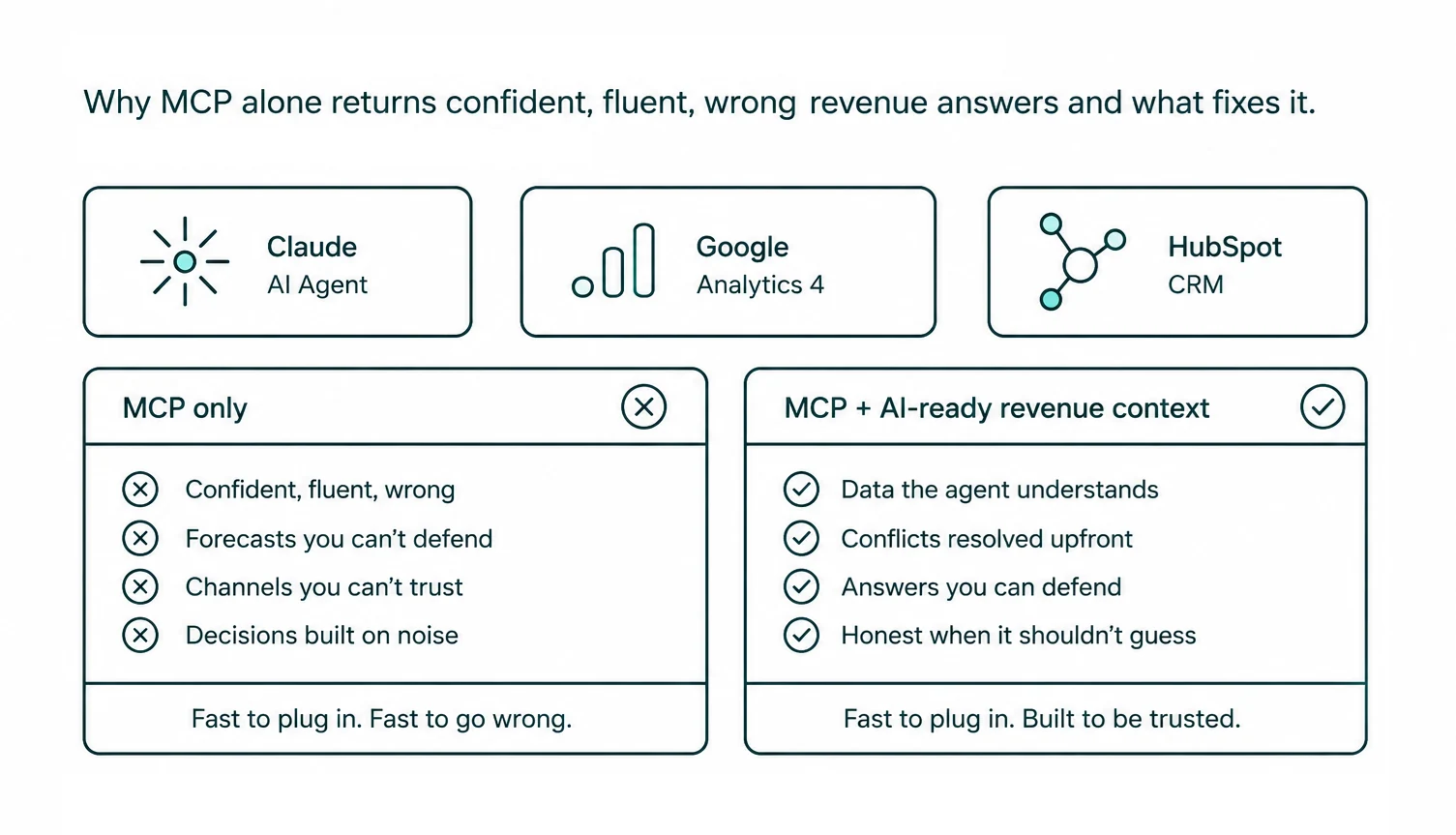
Why raw HubSpot and GA4 data makes AI agents hallucinate
AI agents hallucinate on raw HubSpot and GA4 data because the model has no way to know which of your inconsistent records reflect reality and which are artifacts of how the system was set up. It reads structure, not meaning. The result is fluent answers built on flawed assumptions, and the failure mode is uniquely dangerous because the answers sound right.
Three patterns show up almost every time.
Pattern 1: Source fields that hide where buyers actually come from
In B2B, a large share of Direct traffic in HubSpot is actually unattributed: LinkedIn, Slack communities, podcasts, touchpoints where the referrer is lost by the time someone fills a form. HubSpot records them as Direct because that's what the URL says. A human reading 60% Direct in a revenue report knows to treat it as an attribution gap. An AI agent doesn't. It reports Direct as the top channel and recommends doubling down on it.
A raw MCP connector will pass that 60% Direct through unchallenged.
A prepared agent does something different: it cross-references, when the context layer knows the pattern is worth checking. If GA4 shows steady LinkedIn traffic to the site, and HubSpot shows a large Direct bucket that doesn't match anything in GA4's referrer data, that's the kind of correlation a metadata note can tell the agent to flag. With that note in place, the agent surfaces it as a hypothesis, not a verdict:
Direct in HubSpot is unusually high. GA4 shows significant LinkedIn traffic over the same period that doesn't appear in HubSpot's source breakdown. This could indicate dark-social attribution loss. Direct might be worth reading as a floor rather than a category. Want me to check the time correlation more closely?
Fixing the underlying attribution requires server-side tracking or paid attribution tools, none of which is a quick win. But teaching the agent to recognise the pattern across systems: that's a metadata layer plus a few cross-system instructions, and it's the difference between confidently wrong and usefully careful.
Pattern 2: How agents turn missing data into wrong answers
Some questions don't have answers in the data, and that's where AI agents become most dangerous, because they don't tell you the data isn't there.
Take closed_lost_reason that's empty on 40% of lost deals. The agent, asked why are we losing deals, reports the categories it can see: pricing, competitor, no decision, plus a fourth bucket called unknown or missing, often the largest. A reader takes that to mean the biggest reason we lose is "unknown." What it actually means is we don't fill the field 40% of the time. The agent didn't lie. It treated empty as a category.
This isn't a problem fixed by improving the data. The data is what it is. It's a problem fixed by changing how the agent answers when the data isn't enough. A prepared agent says:
Of the 60% of lost deals where closed_lost_reason is filled, the top reasons are pricing, competitor, and no decision. The remaining 40% has no recorded reason. I can't tell you why those were lost from the CRM alone.
That answer is harder to write than a number. It's also the one that's worth trusting.
Pattern 3: One customer that exists in the CRM as three
Most HubSpot instances carry duplicate contacts. Someone fills a form in 2024 with one email, comes back two years later with a new email at a new company, gets a manually-created contact with a typo. Three records, one person, and HubSpot doesn't know it.
Asked "how many new customers this quarter?", a raw MCP agent counts rows and returns a single number. The number is wrong, sometimes by a few percent, sometimes more. The agent has no way to know it's counting the same person multiple times.
A prepared agent, told upfront to treat identity ambiguity as a known trap on this CRM, handles it differently. Instead of one number, it gives two (raw count and unique-by-email) and surfaces the gap honestly:
By raw count, the number is X. By unique email, it's Y. The true figure likely sits closer to the deduplicated estimate, but I can't fully resolve identity from this CRM alone.
The fix isn't removing duplicates from HubSpot. That's a cleanup project. It's stopping the agent from quietly averaging over uncertainty it can't see through.
Three patterns, three different fixes:
- Pattern 1 wants cross-system context: here's what GA4 sees that HubSpot doesn't, surface the mismatch as a caveat.
- Patterns 2 and 3 want something most teams never configure: an explicit contract for when the agent should answer I don't know instead of generating a number that papers over the gap.
Together, these patterns (plus encoded business meaning for terms that depend on your team's definitions) are what context engineering produces.
OpenAI's September 2025 paper on why language models hallucinate makes the underlying point clearly: standard training and evaluation reward confident guessing over admitting uncertainty. Models learn to produce plausible answers even when the underlying information is incomplete. The paper explains why models guess. An AI-ready revenue context shows the agent where to stop guessing.
The real problem: context engineering, not prompt engineering
Context engineering is the practice of giving an AI agent the structured information it needs to interpret your data correctly: field definitions, business rules, system boundaries, explicit handling of missing or ambiguous values. For revenue analytics on HubSpot and GA4, it's the difference between an agent that retrieves and an agent that answers.
Most early conversations about AI accuracy focused on prompt engineering, how the question is phrased. That work matters at the edges. But when an agent is reading live revenue data, the bottleneck isn't the prompt. The bottleneck is what the agent knows about the data before the prompt arrives.
A well-phrased prompt against badly described data still gets a confidently wrong answer. A plain-English question against well-described data gets a useful one.
What well-described looks like for an AI agent on HubSpot and GA4:
- Authoritative fields per question. HubSpot and GA4 both have source fields, but they record different things: HubSpot captures the source at form-fill, GA4 captures it at each session. The agent needs to know which field answers which question, otherwise it picks whatever matches the query and reports a number that might be from the wrong system.
- Operational meaning of lifecycle stages, beyond just the labels. What Qualified or Opportunity actually means in this team's process.
- Boundaries between systems. GA4 sessions and HubSpot contacts usually cannot be reliably joined at user level without additional identity infrastructure. The agent should surface that gap when asked, not paper over it with arithmetic.
- An explicit "I don't know" rule. This is the single most underrated piece of context engineering. An agent that reports Direct is your top channel without flagging the dark-social caveat is worse than no agent at all. A prepared one says: The top recorded source is Direct, but Direct in your data is known to include dark social. Read it as a floor, not a category.
That body of structured knowledge is what context engineering produces. It's not a prompt template. It's a layer the agent reads before every query.
Without context engineering, MCP for HubSpot or MCP for GA4 is just a connection cable. The data flows. The understanding doesn't.
What an AI-ready revenue context gives you over a raw connector
A raw MCP connector hands an AI agent direct access to your HubSpot and GA4 data — typically through the underlying APIs, sometimes through a database export or a cached copy, but always with the source's native structure and quirks intact. Everything else (joins, aggregations, source-of-truth decisions, known-bug awareness) has to be reasoned out by the model on every query. That's where wrong answers come from.
An AI-ready revenue context (the term we use for this layer throughout the article) does that reasoning once, ahead of time, and gives the agent something more useful than raw data access. Five concrete things change.
A unified schema across systems. HubSpot API exposes contacts, companies, and deals as three separate endpoints with different fields and different relationships. A prepared layer joins them into one queryable structure with the connections already mapped. The agent doesn't have to figure out the relationship between a contact and a deal every time. It's already there.
Pre-computed datasets for the questions that actually get asked. Deal pipeline rolled up by stage with counts and amounts, raw GA4 events rolled up into session-level records, conversions filtered to a defined list of event names: each one materialised with consistent definitions. A raw agent has to rebuild this scaffolding on every query, costing tokens and producing slightly different answers depending on the path it takes. A prepared agent reads stable, pre-built datasets.
GA4 events flattened into queryable form. Raw GA4 events store key attributes (source, campaign, medium) in a nested structure that requires complex queries to unpack. Every such query is a chance for an agent to lose its way. A prepared layer flattens these into clean columns the agent can read directly, so source questions don't depend on the model writing SQL it's likely to get wrong.
Conversions defined deliberately. Which events count as conversions (form submissions, demo requests, sign-ups) is a business decision, not a query parameter. A prepared layer makes that decision once, documented, so every conversion question is answered against the same definition. A raw agent would either ask the user every time or pick something plausible-sounding.
Documented data traps in metadata. This is where the I don't know contract lives. Notes the agent reads before answering: Direct traffic in this CRM often includes LinkedIn when the tracking script breaks at the form redirect. GA4 and HubSpot can't be reliably joined at user level without additional identity infrastructure. A raw agent has none of this. It reports Direct as 60% and recommends doubling down.
The point isn't that an AI agent on this layer is smarter. It's that the layer has done the careful thinking once, in writing, so the agent doesn't reinvent it (and get it wrong) on every query.
The risk most teams underestimate: a raw MCP connection without this layer is more dangerous than the static dashboards it replaces. A human reading a chart catches the wrong number automatically. That can't be right, our revenue from Direct doesn't look like that. An AI agent has no such filter. It reports the wrong number with confidence, in plain English, often to people who weren't going to verify it.
In many revenue workflows, if the choice is between a static dashboard a human reviews and an AI agent reading raw HubSpot and GA4 without context engineering, the static dashboard is the safer answer. The agent is faster, more conversational, and more wrong, in ways that take longer to catch.
Metadata, semantic layer, and what's realistic for your team
There are three paths a B2B SaaS team can take to get AI-readable revenue data. They cost different amounts, take different time, and produce different levels of trust. Most teams sit at one extreme without realising the middle option exists.
| Raw MCP connection | AI-ready revenue context | Full enterprise semantic layer | |
|---|---|---|---|
| What it gives the agent | Access to data | Documented field meanings, business rules, missing-value handling, I don't know contract | Versioned, governed metric definitions as code |
| Tools / approach | MCP servers, AI connectors, n8n workflows | Metadata layer + AI-ready preparation + business notes | Cube, dbt metrics, LookML, AtScale |
| Setup time | Hours | Days to a few weeks | Months |
| Cost | Near-zero (DIY) | Low (project-based, not retainer) | High (dedicated data team + tooling) |
| Hallucination risk on revenue questions | High (confident wrong answers) | Low (agent flags gaps instead of inventing) | Lowest (every metric has one definition) |
| Right for | Experimentation, descriptive questions on clean fields | Small / mid B2B SaaS that need trustworthy AI revenue answers without an enterprise data stack | Enterprises with a dedicated analytics engineering function |
The middle column is where most B2B SaaS founders actually live, and where almost no one is positioned to help them. Cube, dbt metrics, and LookML are excellent. They're also serious engineering commitments with team requirements that don't match a 30-person startup. Skipping straight to a raw MCP connection saves the money and ships the agent, but produces the wrong-answer pattern this article is about.
How LamparaLab builds AI-ready revenue context — and how far we extend it
We sit between columns two and three of the table above. Connecting your data delivers the middle column — an AI-ready revenue context wired to your HubSpot and GA4, ready for the first insights call. By that point we've already built the layer described earlier: the unified schema, the pre-computed datasets, the documented data traps, the I don't know contract for the gaps that can't be closed with data alone. That is the baseline, not the ceiling.
Beyond the baseline, we extend the same layer through additional discovery. Claude reads the prepared data and surfaces the ambiguities — places where the metadata is silent, fields that mean different things in different reports, definitions the team uses but has never written down. Those become a focused list of questions. A one-to-two-hour interview with RevOps answers them. The answers get encoded into the metadata. Within days or weeks, depending on the complexity of the revenue model, the agent has the business meaning it was missing.
Over multiple rounds, the layer grows. The metadata gets denser. The known-trap catalog expands. The business rules become more specific. On the questions an AI agent actually answers, the gap between this and column three's enterprise build narrows.
What we don't build is column three's infrastructure: multi-consumer governance, declarative metric definitions readable by BI tools, a dedicated analytics-engineering retainer. If your goal is an AI agent that answers revenue questions correctly — not a versioned metric catalog used by Tableau and Looker — that infrastructure is overhead you don't have to pay for.
Where your data lives. Your HubSpot and GA4 data is mirrored into a per-client encrypted store under our control, refreshed on a schedule we agree with you. We never write back to your source systems, and the prepared layer is isolated per client. Data residency, retention, and access scopes are part of the onboarding conversation, not an afterthought.
That's what we do. The work is in the layer, not the connection.
Common questions
How do I connect Claude to HubSpot or GA4?
Both connections work through connector tooling — typically an MCP server (Model Context Protocol) or a similar adapter: a small service that exposes the source's data to Claude over a structured protocol. For HubSpot, a polished MCP server exposes contacts, deals, companies, and properties; authentication runs through your HubSpot account. For GA4, equivalent adapters use the GA4 Data API to expose sessions, events, conversions, and traffic sources; authentication runs through a Google service account. In both cases setup takes minutes. Making the answers trustworthy is a separate piece of work.
What is an MCP server?
An MCP server is a small service that translates between an AI agent like Claude and a data source like HubSpot or GA4. It exposes the source's capabilities as tools the agent can call (read deals, query sessions, fetch properties) using a standardized protocol. MCP is what makes AI agents able to read live business data without custom integration code.
What is a semantic layer?
A semantic layer is a centralized, governed definition of what every business metric and entity means, expressed as code that downstream tools (dashboards, AI agents, BI platforms) read consistently. It sits between raw data and the people or systems asking questions, so that revenue, qualified lead, or active customer mean the same thing everywhere. Tools like Cube, dbt metrics, LookML, and AtScale implement semantic layers. They produce the highest trust but require dedicated engineering time and an ongoing team to maintain them.
Do I need a semantic layer to use AI on my CRM data?
In the long term, ideally yes: versioned metric definitions are the most reliable way to make any analytics, AI or not, trustworthy. In the short term, full semantic layers are expensive enough that most small and mid-sized B2B SaaS teams can't justify them. The middle path is AI-ready revenue context: metadata, business rules, and a controlled tool surface that gives an AI agent enough understanding to answer most revenue questions correctly, without the cost of a full enterprise build.
Can AI-ready revenue context grow into a full semantic layer?
Functionally, on the questions an AI agent actually answers, yes. Multiple discovery rounds extend the metadata, encode more business rules, and refine entity definitions until the answer quality converges with what a Cube or dbt build would produce. As a piece of enterprise tooling (versioned metric definitions in code, governance workflows, BI integrations beyond AI), no, that's a different product on a different timeline. The honest framing: an AI-ready revenue context is not a semantic layer, but for an AI agent reading HubSpot and GA4, the practical gap is smaller than the tooling difference suggests.
Why does Claude give wrong revenue answers from my CRM?
Claude gives wrong revenue answers from your CRM when the data it's reading is inconsistent, partially populated, or differently labeled than the business meaning behind it. The model doesn't invent numbers. It reports what the data says, treating field labels as definitions. When Direct traffic includes untracked LinkedIn, when closed_lost_reason is blank on 40% of lost deals, when one customer exists as three duplicate contacts, when GA4 and HubSpot can't be reliably joined at user level: the agent's answer reflects that, fluently and without flagging the problem. The fix isn't a better prompt. It's context engineering underneath the agent.
How long does it take to make Claude reliable on revenue data?
Wiring up MCP or an equivalent connector takes minutes. Connecting your data into a working AI-ready layer across your HubSpot and GA4, plus a first insights call, is the part that takes real work. Deeper analysis (extended discovery, more business rules encoded, broader catalog of tracking caveats) is scoped separately. A full enterprise semantic layer build (Cube, dbt) is a months-longer separate decision.
Read next
Ideal Customer Profile Framework for B2B SaaS: The ICP-to-Revenue Journey
An ideal customer profile framework for B2B SaaS that reverses customer journey analysis — start from Closed Won deals, derive your ICP from real revenue, then connect HubSpot and GA4 backward to find the patterns that produce revenue.
Revenue Reports Don't Lead to Decisions - How I Use SPICED to Fix That
Revenue reports show what happened, but rarely explain what to fix or what it costs. Here's how I use SPICED with GA4 and HubSpot data to turn funnel metrics into revenue decisions for B2B SaaS.